Írta: Sós András
2019. március 20. 12:54:08 CET
Az ipari IoT eszközök gyártói feltűnően sok erőforrást ölnek abba, hogy az eszközeiket könnyen lehessen felhőalapú szolgáltatáshoz csatlakoztatni. Ez némileg ellentmond annak a tapasztalatunknak, hogy az ipari szereplők nem szívesen látják az adataikat a gyár falain kívül. De hol van az igazság? Az eszköz gyártók látnak a jövőbe, amikor azt gondolják, hogy ez az ellenállás meg fog törni? Vagy ez soha nem történhet meg?
Úgy döntöttünk, hogy amíg a gyártó cégek ezen vívódnak, mi előremegyünk, puding próbát tartunk az Alizzal (korábban Doctusoft), és egy OEE-szerű kísérleti rendszert fejlesztünk.
A terv az volt, hogy egy nagyon egyszerű OEE kezdeményt állítunk össze, mindössze azért, hogy megnézzük, mennyi időbe és mennyi izzadságba kerül. Mi értünk az adatgyűjtéshez, és ismerjük az iparvállalatok igényeit, az Aliz ismeri és használja a Google felhőalapú szolgáltatásait. Kész a nyerő páros.
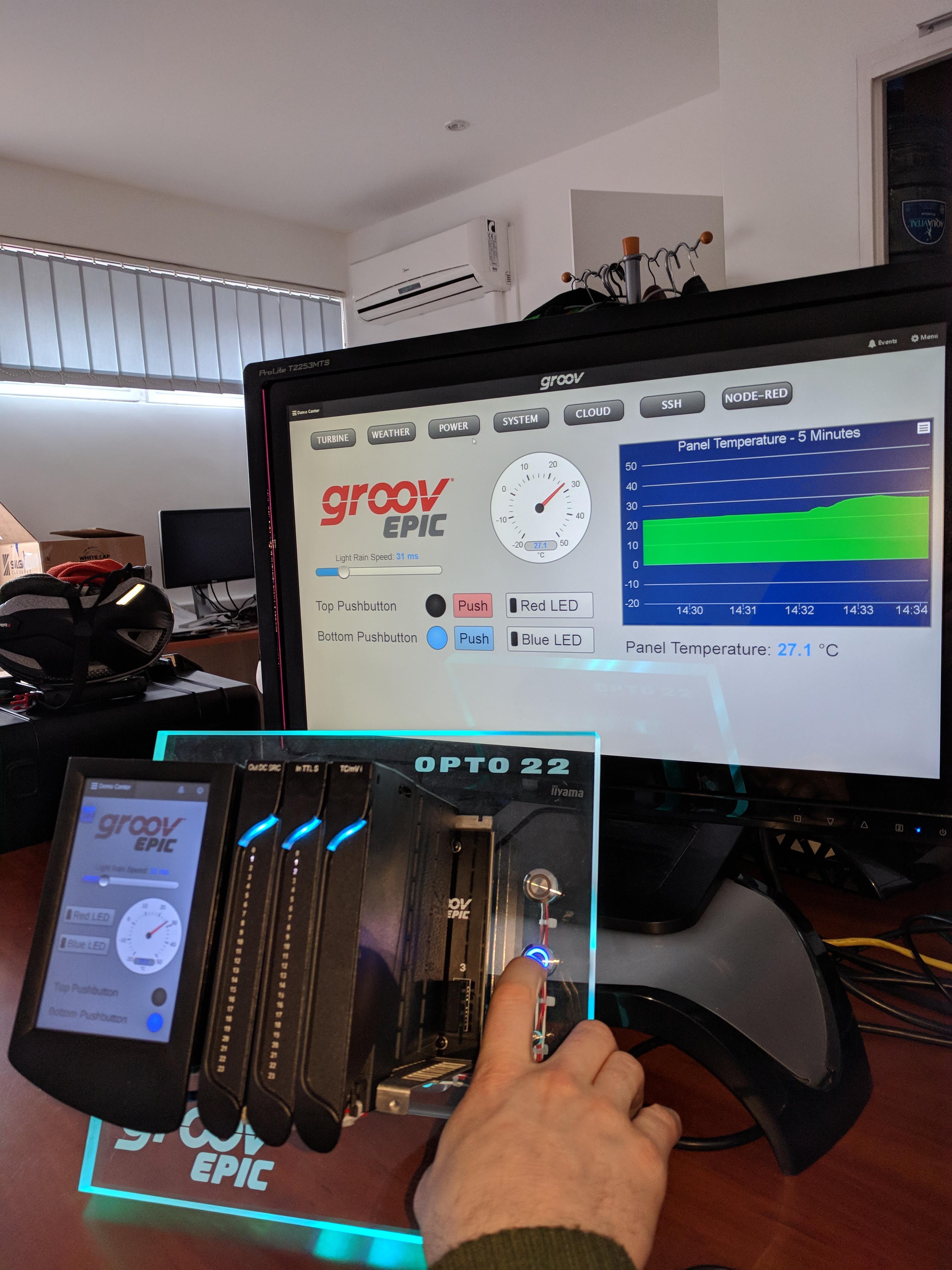
Az adatgyűjtéshez két megoldást választottunk. Az egyik egy univerzális ipari IoT eszköz, egy edge device, az Opto22 nevű gyártó groov EPIC rendszere. A másik egy modulárisan, igények szerint összerakható, MOXA eszközökre alapuló megoldás.
Az első esetben olyan eszközt választottunk, amely alkalmas az automatizálási és vezérlési feladatokon túl adatgyűjtésre szenzorokból, más PLC-kből, OPC szerverből, vagy szinte bármely más adatforrásból. Van benne egy HMI motor, amellyel villám sebességgel lehet felhasználói felületeket készíteni, és az érintőkijelzőn vagy webes felületen megjeleníteni. Ezen kívül fut rajta egy Node-RED szerver (lásd a keretes írást), amellyel programozási ismeretek nélkül lehet összekattintgatni az adatfeldolgozó logikát, és a feldolgozott adatokat percek alatt tudjuk továbbküldeni felsőbb szintű rendszerekbe, SQL szervernek, vállalatirányítási rendszernek, központi adatgyűjtőnek, vagy akár felhőalapú szolgáltatásoknak. Az EPIC azért remek választás, mert olyan PLC programozóknak készült, akiknek nincs ideje leülni megtanulni a HTML, JavaScript, CSS, Python és hasonló nyelveket, és a hozzájuk tartozó fejlesztői környezeteket és könyvtárakat, viszont szeretnének kitörni a PLC nyújtotta szűkös lehetőségek közül. Másrészt olyanoknak is készült, akik meglehet, otthonosan mozognak a webes technológiában, kevéssé ismerik a PLC-ket, ezért túl nagy falat TIA Portált vagy Sysmacot tanulni egy egyszerűbb PLC-s feladat megoldásához. Lássuk be, senki sem érthet mindenhez.
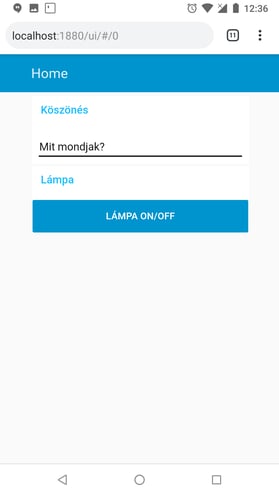
A Node-RED egy olyan nyílt forráskódú fejlesztői környezet, amelyet azért fejlesztettek ki, hogy az IoT-zás közben felmerülő adatfeldolgozást megkönnyítsék. Hiszen miről szól az IoT? Jönnek adatok, azokkal valamit csinálnunk kell (például szűrni, kalkulációt végezni velük, összevetni más adatforrásokkal), aztán a létrejövő új adatokat valahova el kell küldenünk. Ehhez a Node-RED előtt programozási tudás kellett. A Node-RED óta viszont mindössze józan ész. A Node-RED fejlesztés jelentős részét az IBM mérnökei végzik, és az IBM hivatalosan is elkötelezte magát a projekt mellett, ami az open-source világban egy életbiztosítással ér fel. A Node-RED-es fejlesztéshez csak böngészőre van szükség, a futtatáshoz pedig - IoT alkalmazás lévén - egy Raspberry is elég, de saját szórakoztatásunkra mi a telefonunkra is feltelepítettük, és egymás lámpáját kapcsolgattuk (lásd jobbra és alább).
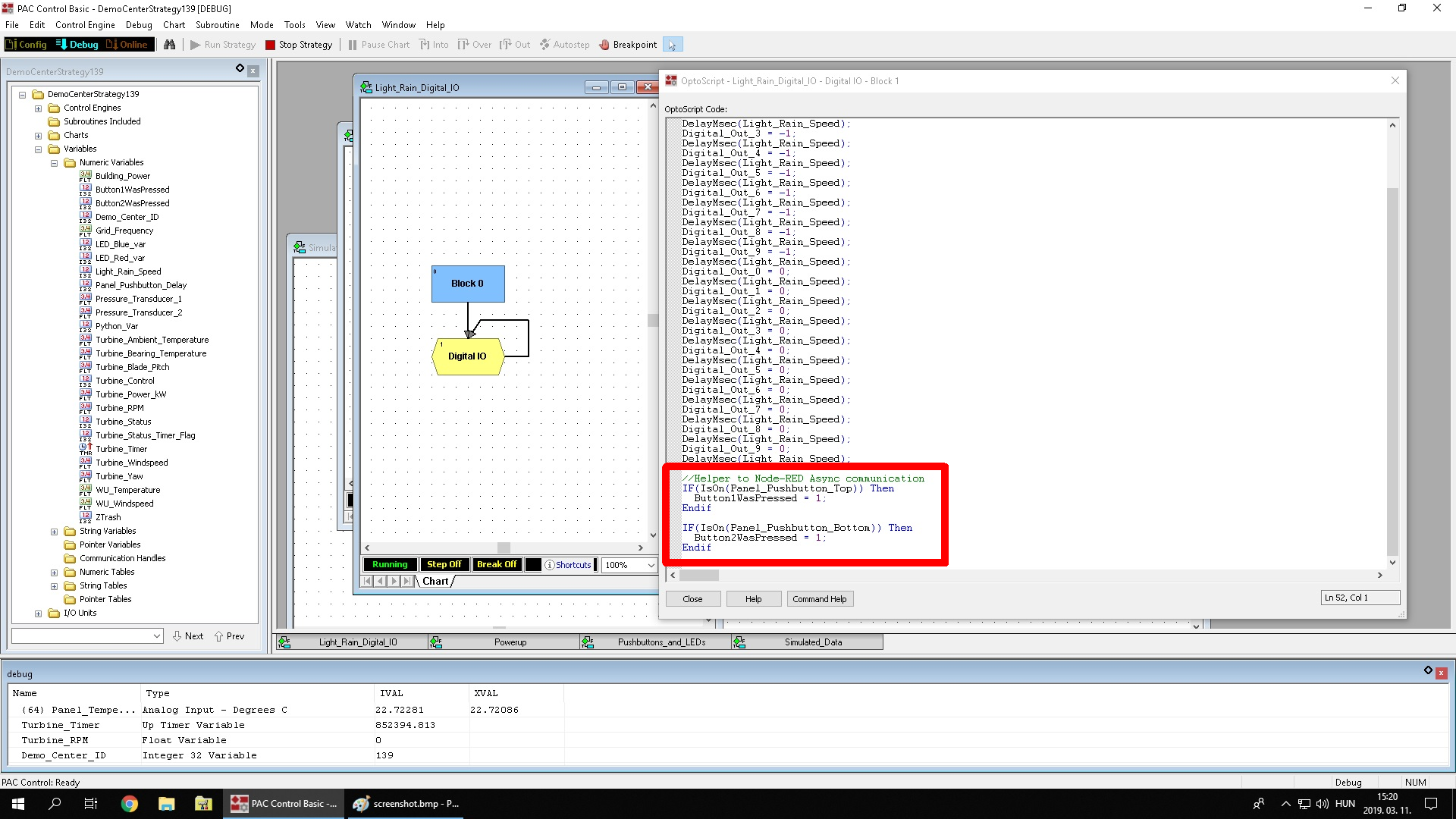
Először Is vettünk egy groov Demo Centert, amely tartalmaz egy digitális kimeneti, egy bemeneti és egy hőmérséklet bemeneti modult, és természetesen a csoda CPU-t. Tartozik még a csomaghoz egy hőelem és 2 LED-es nyomógomb is.
Megírtunk egy olyan vezérlő programot, amely az egyik gombot megnyomva szimulál egy “jó termék kész”, a másik gombot megnyomva egy “hibás termék kész” jelet.
Node-RED-del írtunk egy egyszerű kis adatfolyamot, amely figyeli, hogy érkezett-e “jó” vagy “rossz termék kész” jel. Ha érkezett, akkor azt visszatörli, és küld egy üzenetet MQTT-n keresztül a Google IoT Core szolgáltatásnak. Itt megjegyezném, hogy az MQTT-nek van egy elosztott, Kafka névre keresztelt nagy testvére. Az EDGE-re még egy Kafka brókert is sikerült telepíteni, és annak továbbküldeni az adatokat, ami ismerve a Kafka hardver igényét, hatalmas piros pont az EPIC terhelhetőségének. (Az MQTT-ről, a Kafka-ról és a Google IoT Core-ról lásd a keretes írásokat)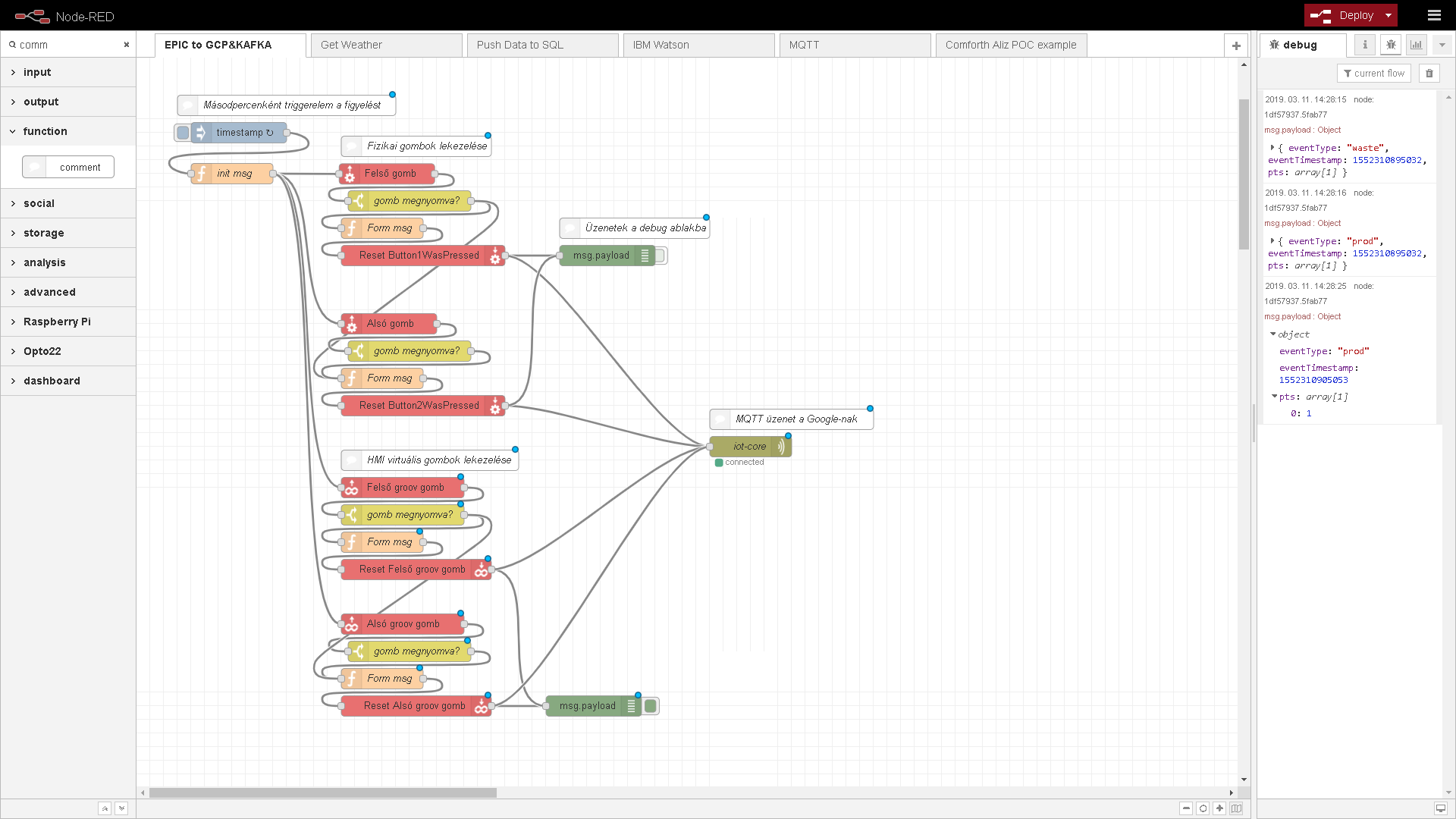
E mellé készítettünk még egy Node-RED flow-t, amely szabályos időközönként hibás és jó darabokat szimulál, és küld fel a felhőbe. Ez azért kellett, hogy akkor is legyen adat, ha épp nem akarunk nyomkodni.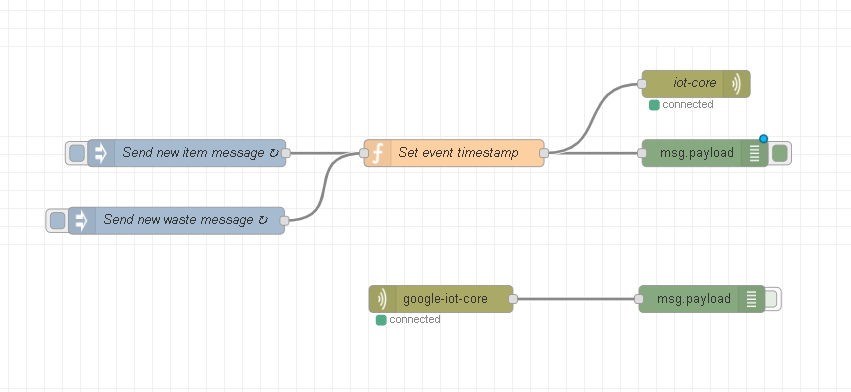
Még mindig az EPIC beépített funkcióit kihasználva készítettünk egy felhasználói felületet, ahol nyomon lehet követni a nyomógombok állapotát, illetve lehet szimulálni gombnyomást arra az esetre, ha a kedves olvasó távolról szeretné kipróbálni a demót.
Felhasználónév: vendeg, jelszó: vendeg.
Az EPIC-nek 2 Ethernet portja van, melyek egymástól függetlenek, nincs köztük route-olás, ezért biztonsággal csatlakoztathattuk az egyik Ethernet portot a Com-Forth iroda belső hálózatára, a második portot pedig egy Internet felé kifelé is nyitott hálózatra, így egyszerre csatlakozhatott volna más PLC-khez, és akár publikálhatja is a feldolgozott adatokat az Interneten, mindezt teljes biztonsággal, mert még az Internet felé nyitott hálózatban sem kell befelé portot nyitni, mivel az MQTT protokoll ezt nem igényli. (A mi esetünkben a 443-as portot meg kellett nyitni, hogy a HMI elérhető legyen távolról)
A Pub/Sub, mely a publish/subscribe, azaz publikálás/feliratkozás, arra utal, hogy az adatküldők beregisztrálják magukat egy szerveren (a brókeren, egy nagyobb teljesítményű számítógépen), hogy küldeni szeretnének adatokat, az érdeklődők pedig azt regisztrálják a brókeren, hogy milyen adatok érdeklik őket. Innentől a küldők a brókernek küldenek csak adatokat, a bróker pedig gondoskodik róla, hogy az adat eljusson a feliratkozókhoz. Minden eszköz lehet publikáló, feliratkozó vagy mindkettő. A Pub/Sub technológia nem új, jóval azelőtt kitalálták, mielőtt még a csapból is IoT-lé folyt.
1999-ben, egy IBM-es és egy Cirrus Linkes mérnök olyan Pub/Sub protokollt fejlesztett saját munkájuk megkönnyítésére, amely kis erőforrás-igényű, gyenge adatkapcsolat esetén is megbízható, továbbá a kapcsolat megléte monitorozható, bármilyen adattípus átfér rajta, könnyű implementálni, és támogatja a QoS-t. Ez lett az MQTT. Ezen tulajdonságai miatt hamar felkapta az IoT, egyre több kis IoT eszközben kezdték használni, így az M2M (Machine to Machine: gépek közötti közvetlen kommunikáció) de facto szabványa lett.
A Kafkát ezzel szemben a LinkedIn azért fejlesztette ki, hogy hatalmas mennyiségű adatot tudjon Pub/Sub rendszerben mozgatni és ideiglenesen tárolni. Míg az MQTT implementációk rendszerint kevés erőforrással is elvannak, a Kafka több erős szervert igényel. Cserébe viszont garantálja, hogy minden üzenet villámgyorsan célba ér, akár több millió előfizető esetén is.
A Kafka mellett más megoldások is léteznek, amelyek támogatják a Pub/Sub-ot: IBM WebSphere MQ, Rabbit MQ, cloud szolgáltatók pedig saját megoldásokkal támogatják a módszert, például a Google a "Google Pub/Sub" szolgáltatásával.
A jól bevált, robusztus Pub/Sub megoldások kiegészítőjeként szokták alkalmazni az MQTT-t a limitált erőforrással és/vagy sávszélességgel rendelkező eszközök integrációjára.
A pub/sub alternatívája a pollozás, azaz kérdezgetés, amikor rendszeres időközönként kérdezgetjük az adatforrást, hogy van-e közölnivalója. A pollozás hátrányaira gondolom, kár is szót fecsérelni.
Az eredményt alább láthatod. Ha megnyomom az alsó gombot, akkor világít a gomb kék LED-je is (ezt a vezérlő csinálja, nem a gomb), és kéken világít az EPIC saját kijelzőjén is és a számítógépem képernyőjén is. Ami még nem látszik, hogy a háttérben az adatok mennek fel a felhőbe.
Ezzel kész is voltunk, következhetett az Aliz. Ők MQTT-n megkapták a következő szöveges (JSON) üzenetet:
{"eventType":"prod","eventTimestamp":1552310905053,"pts":[1]}
Hibás darab esetén az eventType: “waste”.
Arról, hogy ezt az üzenetet hogyan dolgozták fel, tárolták le, és használták fel az OEE adatok megjelenítéséhez, hamarosan olvashattok az ő kezük nyomán. Hogy tartogassunk izgalmakat, a dashboard url címét még nem árulom el, csak az alábbi kiszivárogtatott fotót!
Részünkről a feladat olyan gyorsan megvolt, hogy mérni sem tudtuk az időt. A terv az volt, hogy majd utólag összeszámoljuk, hány mérnöknap volt, de 2-3 óra alatt kész is lettünk. Ahogy a dédnagyapám mondta, jó szerszámokkal gyorsan és szépen lehet dolgozni. Ő asztalos volt, valószínű nem a groov EPIC-re értette. Bár ki tudja...
A Google sem akart lemaradni az IoT-ról, ezért gyorsan készített magának egy MQTT brókert, melyet IoT Core névre keresztelt. Ezen a szolgáltatáson keresztül lehet adatokat beküldeni a többi felhő szolgáltatás számára. Persze a többi felhő szolgáltatónak is van hasonló tudású terméke, az AWS-nél szintén IoT Core, a Microsoftnál Azure IoT Hub névre hallgat.
Az MQTT-n érkező adatokat praktikusan a Kafkához hasonló üzenetelosztóba érdemes küldeni, onnan pedig már mehet a tárolás és a feldolgozás is a szokásos úton. Az üzenetküldőt a Google és az AWS Pub/Subra, a Microsoft Service Busra keresztelte.
Ahogy azt már korábban írtam, 2 különböző hardver architektúrával próbálkoztunk. A fenti volt az egyszerűbb, mert minden egyetlen készülékben, előtelepítve rendelkezésre állt.
A másik megoldás, hogy a szükséges hardver elemeket összeválogattuk a MOXA kínálatából.
Mire volt szükség?
Egy távoli IO-ra, amely a gombokhoz tud csatlakozni. Erre egy MOXA ioLogik E1210 éppen alkalmas.
Egy beágyazott számítógépre, amelyre fel tudtuk telepíteni a Node-RED-et, amely ellátja az adatfeldolgozási feladatokat. Ehhez a legkisebb tudású MOXA beágyazott PC, az UC-2101-LX elegendő.
Mivel nem akartunk honlapot programozgatni a gombok állapotának a kijelzéséhez, és szimulálásához, úgy döntöttünk, hogy a megjelenítést is a Node-RED-re, annak is a Dashboard komponensére bízzuk. A Node-RED Dashboard egyszerűbb megjelenítésekre használható, tudása megáll a mögötte futó Node-RED flow-k értékeinek a megjelenítésénél és azok értékadásánál. Nekünk azonban ebben az esetben ez éppen elegendő volt. Akinek megtetszik a Node-RED Dashboard, és olyan feladathoz használja, amihez nem elég a beépített funkcionalitása, az persze gyárthat egy weboldalt, amibe egy iframe-mel beágyazhatja a Dashboardot, így a kecske is jóllakik, és a káposzta is megmarad.
Mivel az ioLogiknak 2 Ethernet portja van, amelyek switchként funkcionálnak, nem is kellett külön switchet tenni melléjük.
Nehézséget az EPIC-es megoldáshoz képest csak az jelentett, hogy a MOXA beágyazott gépén nincs előtelepítve a Node-RED, sőt a teljes értékű PC-n bevett egysoros telepítési módszer sem működik. Ehelyett le kellett tölteni az ARM processzorra fordított binárisokat, és kézzel kellett beállítani a symlinkeket és környezeti változókat.
Ennek a fejlesztése sem vett több időt igénybe. A Node-RED Dashboard és a groov EPIC felhasználói felületek összeállítását például be is mutattuk legutóbbi IoT szakmai napunkon, hogy a hitetlenek saját szemükkel is meggyőződhessenek, 5 perc alatt el lehet vele készülni!
Nagy a bőség új technológiák terén, nem mindegy, melyik felfedezésével töltjük az időnket. Érdemes a felhőalapú rendszerekkel foglalkoznunk, vagy időpazarlás?
Ma még kevesen kelnek és fekszenek a felhőre gondolva. Ennek egyrészt az az oka, hogy az iparban még nem került be a köztudatba, másrészt az, hogy a termelő vállalatok a szerver hardver beszerzéseket nem tudják megúszni. Ha viszont rendelkezésünkre áll a hálózat, a szerverterem, a szerver maga, az OS és adatbázis licencek is, és nem utolsó sorban a képzett kezelő személyzet, akkor ezeket érdemes ki is használniuk. A felhőnek pedig az egyik legnagyobb előnye az volna, hogy ezekre nem kell beruházni, bérelhetjük az erőforrásokat épp annyi időre, ameddig szükségünk van rá. Akár percekre vagy órákra.
A másik nagy előnye a felhős rendszereknek, hogy nagyon könnyű skálázni. Ha egy-két napra a normál erőforrások százszorosára van szükségünk, az sem okozhat problémát. Ez az online kereskedő rendszereknél hatalmas előny, viszont, őszintén szólva, az iparban ennek nem nagy a létjogosultsága: az adatok általában egyenletesen mozognak ide-oda, mindössze napon belül van ingadozás.
Előnye még a felhőnek, hogy eszközök garmadája áll rendelkezésünkre, legyen szükségünk relációs vagy NoSQL adatbázisra, fájlalapú tárolásra, vagy pub/sub brókerre. Az iparban ez sem tűnik elsőre vonzónak, hiszen akár több tíz éves szabványos kommunikációs protokollok és megoldások vannak segítségünkre (relációs adatbázis = SQL Server, noSQL = histórikus tár, pub/sub = OPC), amelyekkel a legtöbb feladat könnyedén megvalósítható, és az eszközök hosszú távú támogatása biztosított. Ráadásul az automatizálási hardvereket a felhő pont nem olyan bőséggel szolgálja ki (egy tipikus példát a keretes írásban olvashat), hiszen míg az ipari rendszerek hagyományosan Windows-alapúak, a felhő szolgáltatásai szinte mind Linuxra épülnek.
Érdemes azonban ezt az utolsó szempontot kicsit alaposabban megvizsgálnunk. Erre két okunk is van. Egyrészt vegyük figyelembe a számítási kapacitás árának őrült tempójú esését, ami lehetővé tette, hogy akár minden végpontra kihelyezhessünk egy - tipikusan Linuxot futtató - edge device-t. Másrészt, amíg a Microsoft a maga próféciáit követve határozta meg a fejlesztés irányát, addig a linuxos szoftverek óriási választékát fejlesztették ki lelkes végfelhasználók a saját, valós igényeik szerint. Ezzel mára létrejött a Windows ökoszisztéma vetélytársa.
Az iparban használt windowsos protokollok közé tartozik pl. az OPC DA. Ez a rendkívül elterjedt szabvány DCOM technológián alapul, amely nem létezik a linuxos rendszerekben. Talán nem meglepő, hogy a Microsoft nagy erőkkel vett részt a szabvány létrehozásában. Szerencsére rendelkezésre áll ma már az OPC szabvány egy újabb verziója, az OPC UA, amely implementálható bármilyen operációs rendszeren. A SCADA gyártók nagy erőkkel kezdték gyártani a Linuxon, akár beágyazott gépen futó OPC UA szervereket, és a hozzájuk tartozó plug-ineket, hogy minél több PLC-hez lehessen csatlakozni. A Windowsra írt OPC szerverekkel azonban még nem tudják felvenni a versenyt.
Ki kell viszont emelni, hogy a Microsoft az elmúlt években hatalmas változáson ment át. Amik régen elképzelhetetlenek voltak, ma már szinte természetesek: pl. Windowsba épített parancssoros Linux, open-source .NET Core, (egyelőre jóindulatúnak kinéző) GitHub felvásárlás, és az, hogy az OPC UA mellett állnak ki teljes mellszélességgel, hogy csak a legszembetűnőbbeket említsük.
A jövő tehát az, hogy mind nagyobb teret nyernek az iparban a valamilyen linuxos (pl. MQTT) vagy webes (HTTP) protokollon kommunikáló hardver elemek. Egyre könnyebb lesz tehát ezeket az elemeket a natív felhős szolgáltatásokhoz csatolni. Erre csak ráerősít az a trend, hogy a legtöbb új fejlesztésű szoftver kliense már böngészőből elérhető, ezért a terminálok, amelyeket a vastag kliens miatt régebben méregdrága windowsos panel PC-kkel voltunk kénytelenek megoldani, mára már Androidot futtató tabletre vagy Raspbiant futtató Raspberry Pi-re cserélődtek. Mivel egy projekt árába a hardver-költség is beleszámít, a kliens oldalról lassan kiszorul a Windows.
Végfelhasználóként ennek a harcnak csak az előnyeit látjuk, hiszen mindkét oldal hívői hatalmas erőbedobással próbálnak jól használható szoftvereket írni, immár nemcsak azért, hogy a vásárlóikat kiszolgálják, hanem azért is, hogy az ellenkező oldal hívői ne tudják őket földbe döngölni. Egy projektnél a költségbeli különbség jellemzően kicsi, hiszen a nyílt forráskódú rendszereknél a kisebb licensz költséget rendszerint kiegyenlíti a magasabb fejlesztési vagy rendszerintegrációs költség, így a beruházói döntésnél marad a minőség és használhatóság mérlegelése.
A kegyelemdöfést viszont a fejlesztő közösség lassú eltolódása adhatja meg. Ezen a területen a régi motorosok még szinte kizárólag Windowst ismerő programozók voltak. A mai fiatal programozók már sokszor csak olyan rendszereket ismernek jól, amik, ha rendszerfüggetlennek próbálnak is látszani, alapvetően Linuxra íródtak. Terjedőben van a NodeJS, a Python, a Docker, a MySQL, a PostgreSQL, és terjedőben vannak azok a felhőre kifejlesztett, később nyílt forráskódúvá tett technológiák is, mint a Hadoop, a Kubernetes és a Kafka, hogy csak néhányat említsünk. Az újonnan piacra lépő cégek már ezeket az újdonságokat fogják erőltetni, végképp vegyessé téve ezzel a képet.
A legnagyobb ellenállást talán az okozza, hogy a gyártási adatokat a tulajdonosaik nem szeretnék a gyárkapun kívül tudni. Erre lehet megoldás a privát vagy a helyi felhő. Már ma is rendelkezésre áll a technológia, hogy szinte bármelyik felhő szolgáltatást implementáljuk házon belül. Már most van több nagyvállalat (a magas beruházási költségek miatt a kisebbek még nem engedhetik meg maguknak), ahol saját maguk kialakították a kis felhőjüket. Mivel még csak induló beruházásokról beszélünk, nagyon kevés funkcióra képesek, ez így természetes. Ahogy viszont bővül a funkcionalitás, úgy fognak előjönni olyan problémák, amelyekre a publikus felhő lesz a megoldás, és akkor lassan-lassan egyre több szál fogja összekötni a saját felhőt a publikus felhővel. Aztán majd jönnek az átszervezések, a kiszerverzések, majd a visszaszervezések, és jönnek azok a felső vezetők, akik nem is értik, hogy miért költöttek millió dollárokat arra, hogy saját erőből oldják meg azt, amit a publikus felhő a töredékéért kínál.
Gondolhatnánk, hogy ez még messze van, de valójában ez már el is kezdődött. Az előző munkahelyemen Lotus Notes-t használtunk levelezésre is és projekt menedzsmentre is. Aztán egy napon bejelentették, hogy elküldik azt a 100 embert, akik eddig a Lotus Notes rendszert tartották karban, a szervereket eladják nehezéknek fenekezéshez a pecásoknak, a levelezést, a projekt menedzsmentet átviszik a Google-höz, és a pénzt, amit ezzel spóroltak, szétosztják a felső vezetés között. Saját bevallásuk szerint 90% költségmegtakarítást értek el! És egy termelő vállalatról beszélünk, aki a legérzékenyebb adatait kezdte a publikus felhőben tárolni! Tíz évvel ezelőtt!
A rövid válasz a hosszú fejtegetés után: igen, érdemes a felhőalapú technológiákkal foglalkozni, mert pár éven belül elkerülhetetlen lesz. Aki kimarad, lemarad.
Ha úgy érzed, szeretnél egy gyors levágással a versenytársaid elé kerülni, és szeretnéd kipróbálni a fenti koncepciókat, kérjük keress minket! Várjuk az olyan érdeklődők jelentkezését, akik látnak fantáziát az edge computingban és/vagy a felhőben, és hajlandók velünk együtt kísérletezni.
Tudjuk, a téma megosztó és némileg provokatív is. Nagyon érdekelne, hogy mi a véleményed, mi a tapasztalatod. Te mit jósolsz az elkövetkezendő 5-10 évre?
Egy tipikus automatizálással kapcsolatos feladat, hogy PLC-kből adatokat kell gyűjteni, azokat megjeleníteni, és a kezelőnek beavatkozási lehetőséget nyújtani. Egyszóval SCADA-ra van szükség. Míg Linuxon futó SCADA-k már elérhetők (ezek közül külön figyelmet érdemel a magyar fejlesztésű PASS, továbbá az Ignition), linuxos kommunikációs drivereknek, tehát azon szoftver elemeknek, amelyek meg tudják szólítani a PLC-ket, már híján van a piac. A felhőben nem kötelező teljes virtuális PC-ket bérelni, lehet sokkal kisebb egységekre is szert tenni, úgy mint konténer futtatóra, HTTP végpontra, vagy akár egy függvény futtatására, mindaddig, amíg nem kerülnek elő .exe fájlok, COM objektumok és barátaik, amelyek sajnos a hagyományos kommunikációs driverek sajátjai.
Mit tehet hát az egyszeri halandó, ha felhőben akar SCADA-t futtatni? Bérel egy teljes virtuális gépet Windows-zal. Csak hát ezzel az egész felhőzésnek az esszenciája veszik el. Mindenesetre mi kipróbáltuk. Telepítettünk teljes szoftver csomagot a Google felhőbe: iFIX SCADA-t PLC kommunikációval, riasztás kezeléssel, histórikus tárral, böngésző-alapú és vastag klienses megjelenítéssel. Működött gyönyörűen. Telepítettünk Ignition SCADA-t, az is működött. Aztán gyorsan le is töröltük, mert a Windowst futtató virtuális gépeknél drágább szolgáltatást a Google Cloud Platform talán nem is ismer.
Mi a következtetés? Bizonyos cégeknél van ennek a megoldásnak is létjogosultsága, de a tipikus magyar termelő vállalatoknál ilyen formában nem működőképes. A PLC-vel való kommunikációt a PLC közelében kell megoldani, az adatokat előfeldolgozni, és csak utána továbbítani a felhőbe, ha szükséges. Ennek az eljárásnak a neve az Edge Computing (erről lásd a keretes írást előző blog bejegyzésünkben).
Kinek lehet való a közvetlen felhőben SCADA-zás? Azoknak, akiknek 1) újabb és elterjedtebb PLC-ik vannak, 2) a hálózati kimaradás okozta SCADA kiesés nem okoz problémát (a SCADA ilyen esetben nem mission critical), 3) nincs egy erős helyi IT, akik egy perc alatt rendelkezésre tudnak bocsátani egy helyileg futó virtuális gépet.
Akinek újabb, elterjedtebb PLC-i vannak, de a felhőzés nem opció, az pedig telepíthet Linuxon futó SCADA-t sokkal olcsóbb hardverre, akár egy Raspberry PI-re is.
A blogpost során számos témát érintettünk, melyek kidolgozásában nagy segítséget nyújtott Kovács Gergely és Hóringer Tamás fejlesztő kollégám, akiknek ezúton is köszönöm, hogy hozzájárultak szakértelmükkel, hogy ez a cikk létrejöjjön!